StableDiffusionを取り扱う際、そのすべてをStableDiffusion webUIで触ってきました。
しかし世の中にはもう1つ、メジャーなStableDiffusionを扱うGUIが存在しています。
ComfyUI
今回はこのComfyUIをJetson AGX orinで動作させてみたいと思います。なんで今さらComfyUIなのかというと、StabilityAIがリリースするものへの対応が早かったり、その他の画像生成機能への適応が早いなーと感じたからです。
生成AIは非常に流れが早いため、ちょっとでも早くアクセスできる環境を用意しておきたいなと。
また、Windowsと比べるとちょっとインストールなどで情報が得にくいですが、せっかくの大容量のVRAMを活用していきたいのでJetson AGX orinで動作させていきたいと思います。
目次
①やること
ComfyUIをJetson AGX orinにインストールしてとりあえず画像を生成してみる。 今回は以下の記事を参考にさせていただきました。
note(ノート)


ComfyUI : ノードベース WebUI 導入&使い方ガイド|teftef
こんにちはこんばんは、teftef です。今回は少し変わった Stable Diffusion WebUI の紹介と使い方です。いつもよく目にする Stable Diffusion WebUI とは違い、ノードベ…
GitHub
GitHub – Comfy-Org/ComfyUI: The most powerful and modular diffusion model GUI, api and backend with …
The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. – Comfy-Org/ComfyUI
また、最初実行時にAssertionErrorと出て「Pytorch無いよ!」的なことを言われて起動できなかったのですが、Jetsonの公式ページにちゃんと書いてありました。以下のJetson用のPytorchを入れることでエラーは回避できました。
NVIDIA Docs
Installing PyTorch for Jetson Platform – NVIDIA Docs
This guide provides instructions for installing PyTorch for Jetson Platform.
②インストール
②-01. クローンと仮想環境のactivate
まずはGitからComfyUIのデータをクローンしてきます。今回はComfyUIのディレクトリ内に仮想環境を作って実行しようと思うので、クローンが終わったらComfyUIフォルダに入ります。
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI続いて仮想環境を作ります。仮想環境名はcomfyenvとしておきます。
python -m venv comfyenvlsコマンドでディレクトリ内を確認してcomfyenvがあれば作成できています。

comfyenvをactivateします。 ※Linux(ubuntu)なのでWindowsとはコマンドが異なります。
source comfyenv/bin/activate②-02. 仮想環境にJetson用の環境を構築
Jetson用のPytorchの依存関係のパッケージを入れていきます。
sudo apt-get -y update;
sudo apt-get -y install autoconf bc build-essential g++-8 gcc-8 clang-8 lld-8 gettext-base gfortran-8 iputils-ping libbz2-dev libc++-dev libcgal-dev libffi-dev libfreetype6-dev libhdf5-dev libjpeg-dev liblzma-dev libncurses5-dev libncursesw5-dev libpng-dev libreadline-dev libssl-dev libsqlite3-dev libxml2-dev libxslt-dev locales moreutils openssl python-openssl rsync scons python3-pip libopenblas-dev;続いてNvidiaのサイトからJetson用のPytorchを落とします。まずはJetson用Pytorchのダウンロード先を指定します。
export TORCH_INSTALL=https://developer.download.nvidia.cn/compute/redist/jp/v511/pytorch/torch-2.0.0+nv23.05-cp38-cp38-linux_aarch64.whl次にインストールです。
python3 -m pip install --upgrade pip; python3 -m pip install aiohttp numpy=='1.19.4' scipy=='1.5.3' export "LD_LIBRARY_PATH=/usr/lib/llvm-8/lib:$LD_LIBRARY_PATH"; python3 -m pip install --upgrade protobuf; python3 -m pip install --no-cache $TORCH_INSTALL②-03. ComfyUIの残りもインストール
xformersをインストールします。
pip install xformers -U最後に残りのモジュールをインストールして終わりです。
pip install -r requirements.txt③ComfyUIの実行
③-01. checkpointを格納
本当はvaeなども入れなければなのですがとりあえず今回は画像生成ができればいいのでModelファイルだけ入れて画像生成に進みたいと思います。 モデルの格納は以下に格納します。
/ComfyUI/models/checkpoints③-02. 起動
python main.pyセットアップが終わったので起動してみましょう。ComfyUIディレクトリ内で仮想環境をactivateした状態で以下を実行です。問題なければURLが表示されます。

上の表示が出たらブラウザからhttp://127.0.0.1:8188を開きます。ComfyUIの画面が表示されます。
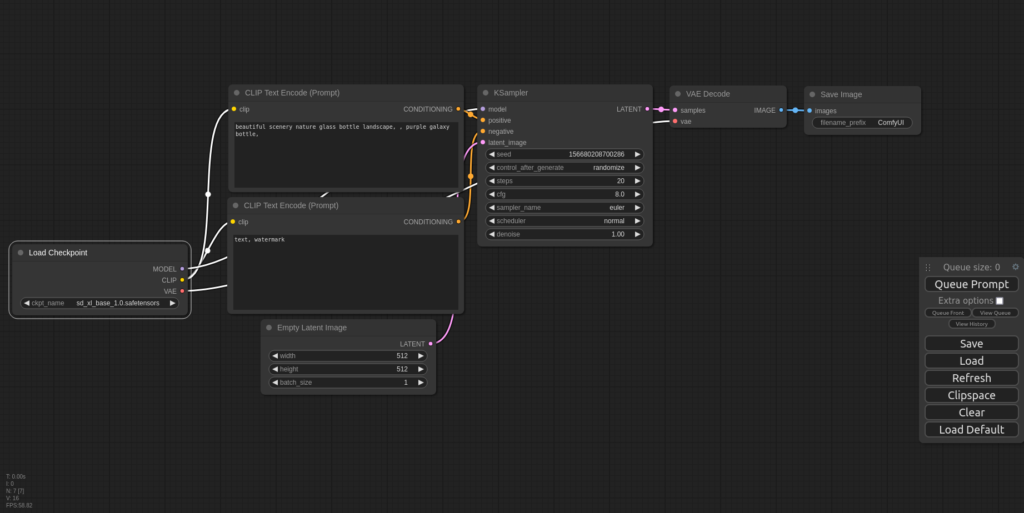
③-03. 画像生成の実行
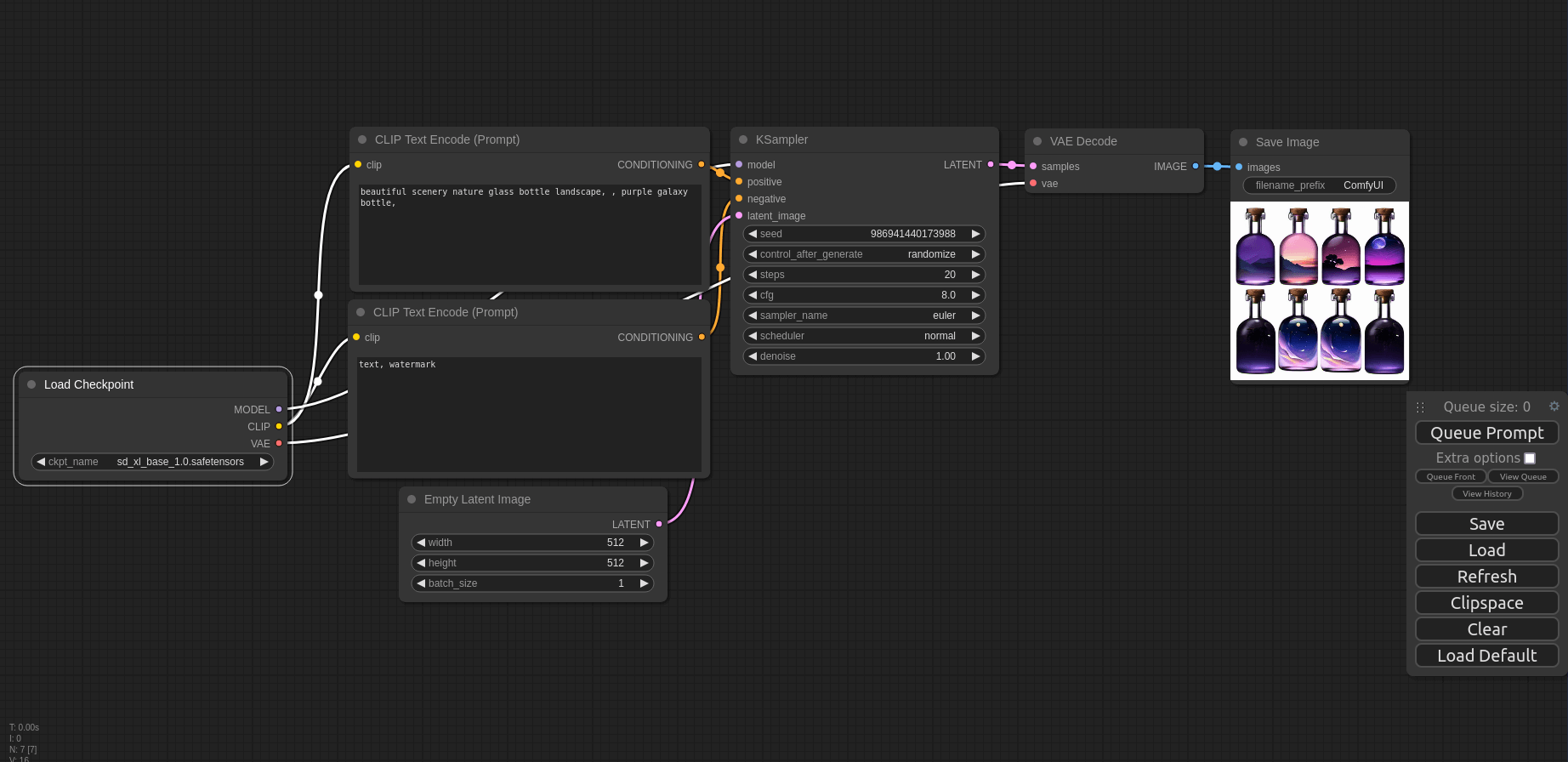
まずは使ってみようの回なのでモデルはStable Diffusion webUIで使っていたSDXLのモデル、sd_xl_base_1.0.safetensorsを使います。 モデル以外は特にいじらずに右にあるボックスの中のQueue Promptを押すと生成が開始されます。 少し待つとSave Imageの枠に画像が生成されます。
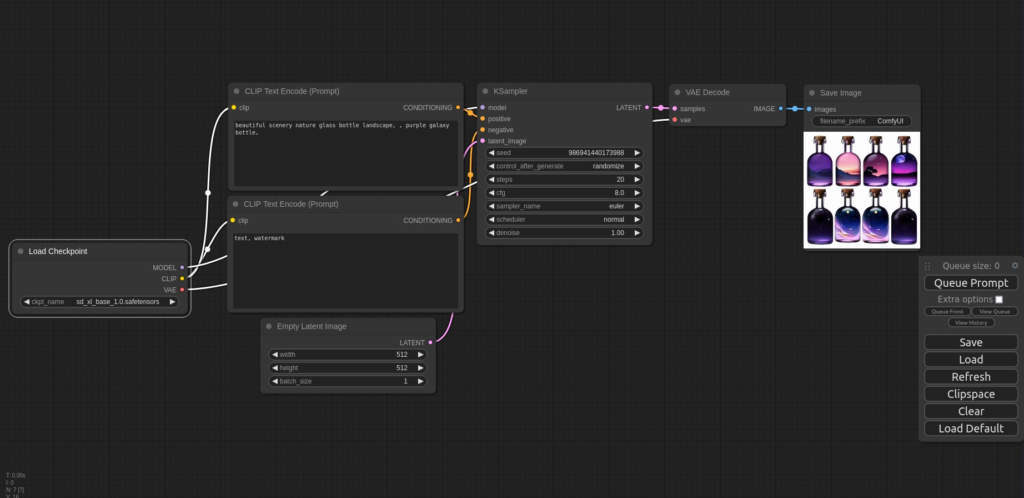
SDXLのモデルを使っていますが初期の解像度が512×512になっていたので小さめの画像が生成されました。サンプルで入っているプロンプトそのままで瓶の中にいろんな夕暮れの景色が入った画像が出てきました。キレイですね!

せっかくSDXLなので画像を1024×1024でも生成します。そうして出てきたのがこちらです。

瓶の中に風景を閉じ込めたような画像が生成されました。ぼかした背景も味があり、ちゃんとイラストレーターが描いたみたいですね。やはりSDXLなので1024×1024のほうがいい生成結果が出るのかな? 一度しか試してないので詳細はわかりませんが、とりあえずインストールと生成の実行が完了です。
④まとめ
ComfyUIで画像を生成してみました。サンプルのプロンプトを最初から入れてくれていたのでとりあえず動かしたい自分にはすぐできてありがたかったです。
Jetson環境でPytorchを認識せず一度諦めたのですが、「Jetson Pytorch」で検索してNvidiaのページに辿り着くことができました。英語なので読むの躊躇ってしまいましたがちゃんと用意してくれている情報を読むだけで苦戦せずに済んだので人の言うことはちゃんと聞かなきゃですね。。
まだStableDiffusionwebUIほど使い方がわかっていないので、LCMを使った高速画像生成やSDXL turboなどをさわりつつ理解していきたいと思います。